TAVA: Template-free Animatable Volumetric Actors
ECCV 2022
- Ruilong Li1,3
- Julian Tanke 2,3
- Minh Vo3
- Michael Zollhoefer3
- Jurgen Gall2
- Angjoo Kanazawa1
- Christoph Lassner3
1UC Berkeley 2University of Bonn 3Meta Reality Labs Research
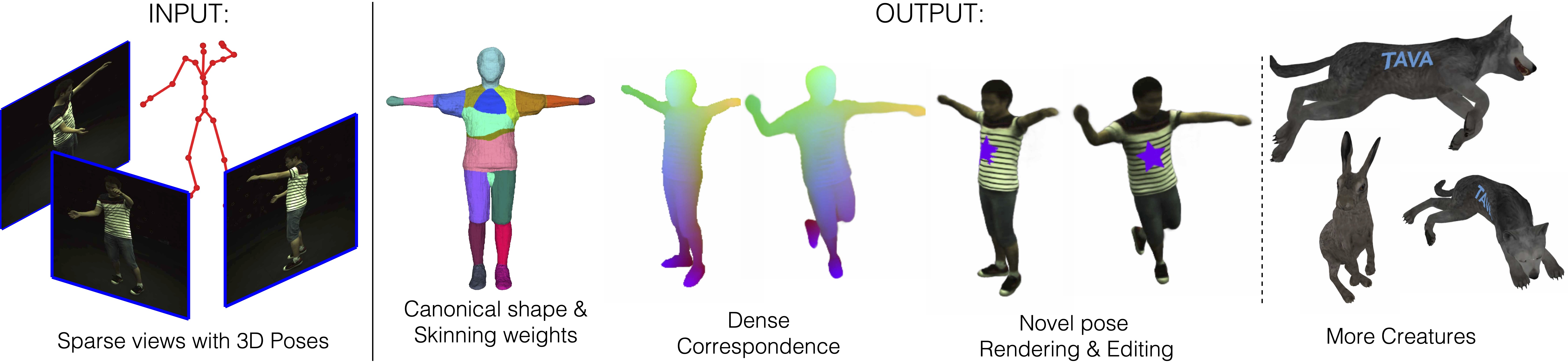
Method Overview. Given multiple sparse video views as well as 3D poses as inputs, TAVA creates a virtual actor consists of implicit shape, apperance, skinning weights in the canonical space, which is ready to be animated and rendered even with out-of-distribution poses. Dense correspondences across views and poses can also be established, which enables content editing during rendering. Without requiring body template, Our method can be directly used for creatures beyond human as along as the skeleton can be defined.
Section I. Novel-Pose Rendering with Dance Motion.
In the video below, we show a demo of reposing multiple learnt actors (left) using the same motion sequence from AIST++ Dance Motion Dataset (right), in which the poses are novel poses and out-of-distribution of the training ones.
* The bended back in our rendering results come from the inaccurate AIST++ motion estimation.
Section II. Dense Correspondences.
In the following videos, we show our results of dense sorrespondences. The colors indicates the canonical correspondences of each pixel.
Section III. Comparisons with Other Methods.
In the following videos, we show comparisons between our method and different baselines on the task of novel-pose synthesis using a sequence of poses never seen during training.
* "Ours (robust)" denotes our results with shading factorized out, thus is more robust to novel pose rendering.
* Both "Animatable-NeRF" and "NeuralBody" require SMPL body templates while other approaches don't.
More Thanks
We thank Hang Gao, Alex Yu, Matthew Tancik and Sida Peng for helpful discussions. We also thank the authors of Mip-NeRF and SNARF for the amazing works which inspires this work. This website is inspired by the template of aichoreographer.